4. 1. Thema 1, Fallstudie 1
Überblick
Sie sind Data Scientist in einem Unternehmen, das Data Science für professionelle Sportveranstaltungen anbietet.
Modelle werden globale und lokale Marktdaten sein, um die folgenden Geschäftsziele zu erreichen:
• Verstehen Sie die Stimmung von Benutzern mobiler Geräte bei Sportveranstaltungen auf der Grundlage von Audio aus den Reaktionen der Menge.
• Greifen Sie auf die Tendenz eines Benutzers zu, auf eine Anzeige zu reagieren.
• Passen Sie die Stile von Anzeigen an, die auf Mobilgeräten geschaltet werden.
• Verwenden Sie Video, um Elfmeterereignisse zu erkennen.
Aktuelles Umfeld
Anforderungen
• Medien, die zur Erkennung von Strafereignissen verwendet werden, werden von Verbrauchergeräten bereitgestellt. Medien können Bilder und Videos enthalten, die während des Sportereignisses aufgenommen und über soziale Medien eingefangen wurden. Die Bilder und Videos haben unterschiedliche Größen und Formate.
• Die für den Modellbau zur Verfügung stehenden Daten umfassen sieben Jahre Sportveranstaltungsmedien. Die Sportereignismedien umfassen: aufgezeichnete Videos, Transkripte von Radiokommentaren und Protokolle von verwandten Social-Media-Feeds , die während der Sportereignisse erfasst wurden.
• Die Stimmung der Menge umfasst Audioaufnahmen, die von Veranstaltungsteilnehmern in Mono und Stereo eingereicht wurden Formate.
Anzeige
• Ad-Response-Modelle müssen zu Beginn jeder Veranstaltung trainiert und während der Sportveranstaltung angewendet werden.
• Marktsegmentierungs -Nxxlels müssen für ähnliche Anzeigenresponsorenhistorie optimiert werden.
• Das Sampling muss gegenseitige und kollektive Exklusivität lokaler und globaler Segmentierungsmodelle garantieren, die dieselben Merkmale aufweisen.
• Lokale Marktsegmentierungsmodelle werden angewendet, bevor die Neigung eines Benutzers bestimmt wird, auf eine Anzeige zu reagieren.
• Data Scientists müssen in der Lage sein, die Verschlechterung und den Verfall von Modellen zu erkennen.
• Ad-Response-Modelle müssen nichtlineare Begrenzungsfunktionen unterstützen.
• Das Werbeneigungsmodell verwendet einen Kürzungsschwellenwert von 0,45 und erneute Schulungen erfolgen, wenn das gewichtete Kappa von 0,1 +/-5 % abweicht.
• Das Werbeneigungsmodell verwendet Kostenfaktoren, die im folgenden Diagramm dargestellt sind:
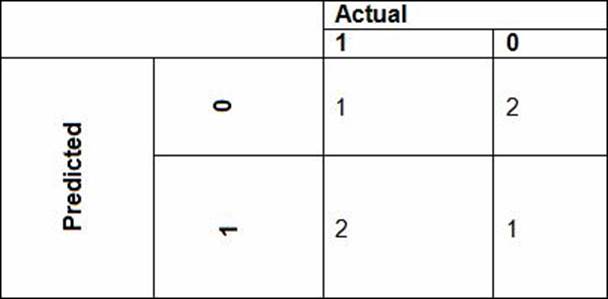
• Das Werbeneigungsmodell verwendet vorgeschlagene Kostenfaktoren, die im folgenden Diagramm dargestellt sind:
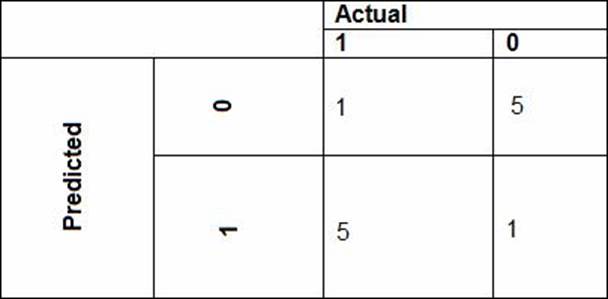
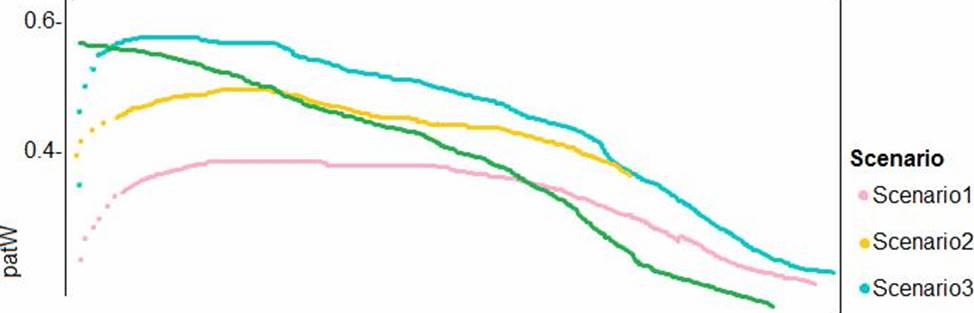
Leistungskurven aktueller und vorgeschlagener Kostenfaktorszenarien sind im folgenden Diagramm dargestellt:
Elfmetererkennung und Sentiment
Ergebnisse
• Datenwissenschaftler müssen eine intelligente Lösung entwickeln, indem sie mehrere maschinelle Lernmodelle zur Erkennung von Penalty-Ereignissen verwenden.
• Data Scientists müssen Notebooks in einer lokalen Umgebung mit automatischem Feature-Engineering und Modellerstellung in Pipelines für maschinelles Lernen erstellen.
• Notebooks müssen zum erneuten Trainieren bereitgestellt werden, indem Spark-Instanzen mit dynamischer Worker-Zuweisung verwendet werden
• Notebooks müssen mit demselben Code auf neuen Spark-Instanzen ausgeführt werden, um nur die Quelle der Daten neu zu codieren.
• Globale Penalty-Erkennungsmodelle müssen trainiert werden, indem während des Trainings dynamische Laufzeitgraphberechnungen verwendet werden.
• Lokale Penalty-Erkennungsmodelle müssen mithilfe von BrainScript geschrieben werden .
• Experimente für lokale Crowd-Stimmungsmodelle müssen lokale Penalty-Erkennungsdaten kombinieren.
• Crowd-Sentiment-Modelle müssen bekannte Geräusche wie Jubelrufe und bekannte Schlagworte identifizieren. Individuelle Crowd-Sentiment-Modelle erkennen ähnliche Geräusche.
• Alle gemeinsamen Merkmale für lokale Modelle sind kontinuierliche Variablen.
• Gemeinsam genutzte Features müssen doppelte Genauigkeit verwenden. Nachfolgende Schichten müssen Metriken für den aggregierten laufenden Mittelwert und die Standardabweichung verfügbar haben.
Segmente
Während der ersten Produktionswochen wurde Folgendes beobachtet:
• Anzeigenreaktionsraten sanken.
• Drops waren in allen Anzeigenstilen nicht konsistent.
• Die Verteilung von Funktionen auf Trainings- und Produktionsdaten ist nicht konsistent.
Die Analyse zeigt, dass von den 100 numerischen Merkmalen zum Standort und Verhalten des Benutzers die 47 Merkmale, die aus Standortquellen stammen, als Rohmerkmale verwendet werden. Ein vorgeschlagenes Experiment zur Behebung des Bias- und Varianzproblems besteht darin, 10 linear unkorrigierte Merkmale zu konstruieren.
Elfmetererkennung und Sentiment
• Die anfängliche Datenermittlung zeigt ein breites Spektrum an Dichten von Zielzuständen in Trainingsdaten, die für Crowd-Sentiment-Modelle verwendet werden.
• Alle Straferkennungsmodelle zeigen, dass Inferenzphasen mit einem stochastischen Gradientenabstieg (SGD) zu langsam laufen .
• Hörbeispiele zeigen, dass die Länge eines Schlagworts je nach Region zwischen 25 % und 47 % variiert.
• Die Leistung der globalen Penalty-Erkennungsmodelle zeigt eine geringere Varianz, aber eine höhere Verzerrung beim Vergleich von Trainings- und Validierungssätzen. Bevor Sie Funktionsänderungen implementieren, müssen Sie die Verzerrung und Varianz anhand aller Trainings- und Validierungsfälle bestätigen.
Sie müssen eine Modellentwicklungsstrategie implementieren, um die Tendenz eines Benutzers zu bestimmen, auf eine Anzeige zu reagieren.
Welche Technik sollten Sie verwenden?